Napotkałem pewien problem pisząc aplikację w Javie która za pomocą JNI odwoływała się do natywnego kodu c++ który generował dużo wątków (ponad 1000) oraz alokował miliony obiektów, grupował i sortował. Aplikacja chodziła na kontenerze w kubernetes na maszynie która ma 64 CPU i 250 GB RAM, natomiast kontener ma do dyspozycji 8 CPU i 8 GB RAM. W pewnym momencie zauważyłem, że aplikacja zaczyna zjadać coraz więcej ramu, aż dochodzi do 8 GB i kubernetes restartuje kontener. Kod c++ był sprofilowany za pomocą valgrind więc założyłem że to nie to, skoro tam nie ma wycieków. Następnym krokiem była analiza JVM, tam też nie znalazłem żadnego wycieku pamięci.
Rozpocząłem analizę procesu w systemie i okazało się, że pmap pokazuje mi:
total 45999828Kczyli proces może sobie zaalokować ponad 43 GB RAMU, a z faktu, że system operacyjny węzła ma wolne ponad 200 GB to proces sobie alokuje coraz więcej pamięci. Z czego to wynika?
Standardowy alokator libc alokuje pamięć per CPU – 8 przestrzeni (Area) * 64 MB. Jest to widoczne w sytuacji gdy tworzonych jest bardzo dużo wątków. Alokator optymalizuje alokowanie pamięci i nie zwalnia bloków pamięci, które potem wykorzystuje do kolejnych operacji. Brzmi nieźle póki aplikacja widzi tyle CPU i RAM co może wykorzystać, niestety w przypadku kubernetesa widzi całość zasobów.
Nie pozostało nic innego jak zacząć szukać rozwiązania i tak doszedłem do jemalloc – doskonale sobie radzi z pamięcią. Nagle aplikacja która po kilku nastu godzinach wykładała się przy 8 GB zaczyna zużywać 1 GB RAM. pmap pokazuje:
total 6979264KBenchmarki wykonane przez h2load również pokazują wzrost wydajności o około ~10%
Wkręcając się w alokatory pamięci szukałem dalej, może coś jest jeszcze lepsze. W ten sposób trafiłem na tcmalloc
Powtórzyłem wszystkie testy, zużycie RAMu nieco większe niż w przypadku jemalloc, ale mniejsze zużycie CPU.
pmap pokazał następującą wartość:
total 9884268Kczyli więcej niż w przypadku jemalloc natomiast benchmark wykonany przez h2load pokazał kolejny wzrost wydajności, tym razem o blisko 25% od jemalloc
Żeby mieć pewność wykonałem dodatkowe testy i sprofilowałem aplikacje. GC w JVM za wiele nie pokazał ponieważ tam nie było zbytniego zużycia pamięci. G1 działa wystarczająco sprawnie, choć daje się, że tym razem jemalloc ma największy wpływ na poprawę wydajności choć jest to znikomy przyrost
Kolejnym testem to benchmark kodu w c++
libc:
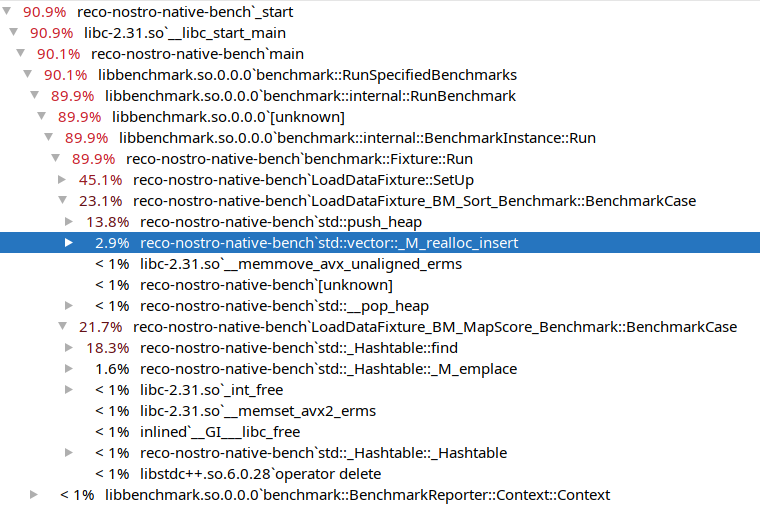
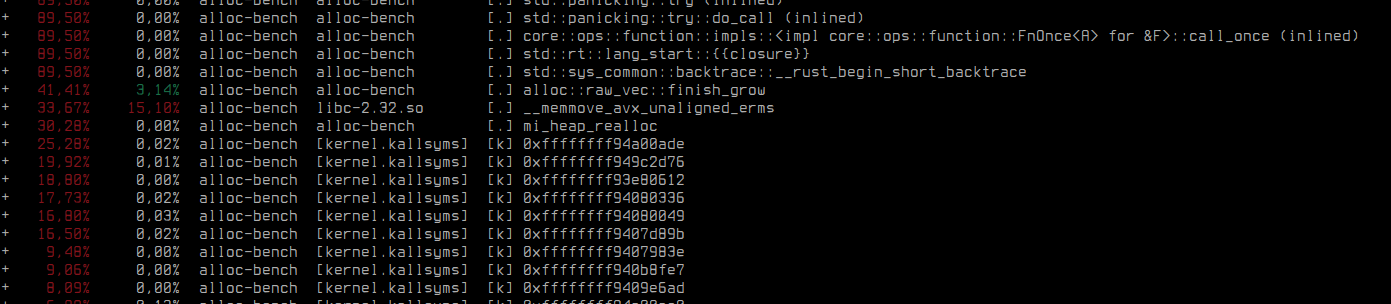
Widać, że funkcja, której głównym procesem jest alokowanie pamięci (13.5%) jest droższa od funkcji sortującej
jemalloc:
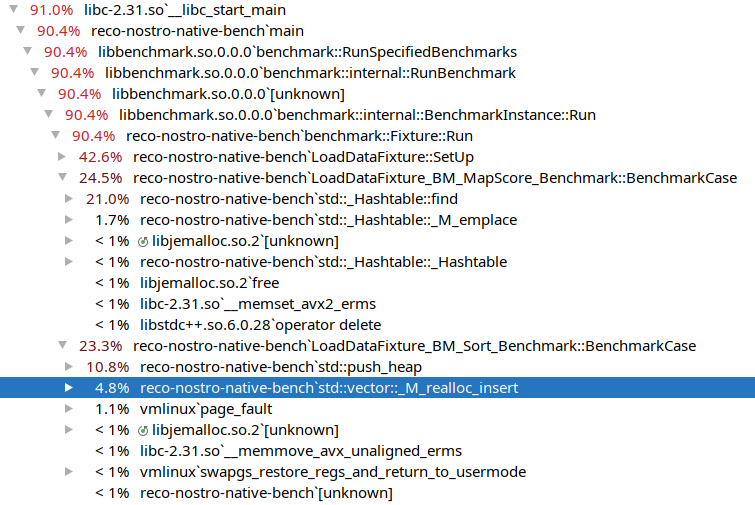
Tu widać, że funkcja sortująca jest droższa niż funkcja alokująca pamięć, funkcja alokująca pamięć zajmuje 4.8%
tcmalloc:
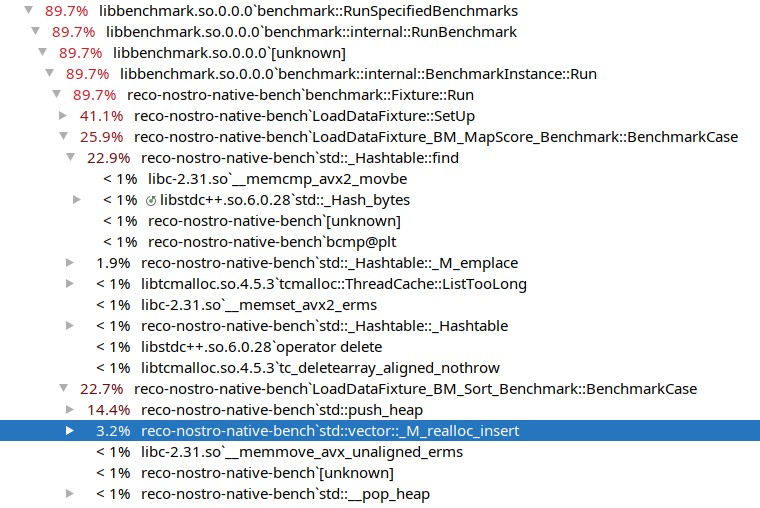
tutaj widać, że różnica pomiędzy funkcjami wynosi 3%, również całkowy czas obu operacji był najkrótszy.
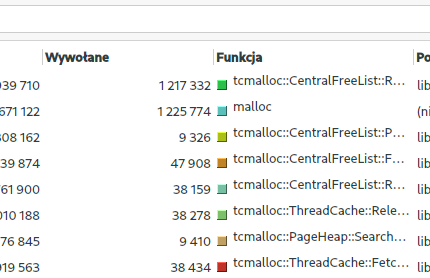
Wywołania funkcji malloc w valgrind:
libc
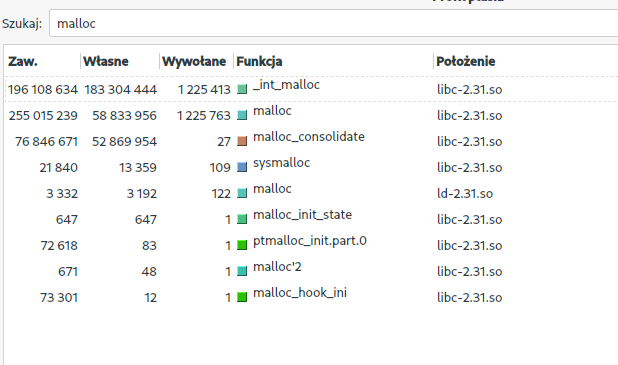
jemalloc
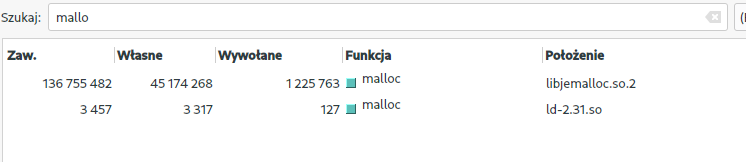
tcmalloc
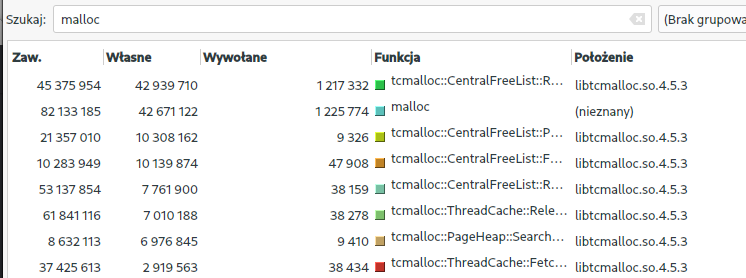
Jak widać ogromna przepaść pomiędzy libc a jemalloc, natomiast między jemalloc a tcmalloc aż tak dużej różnicy nie ma.