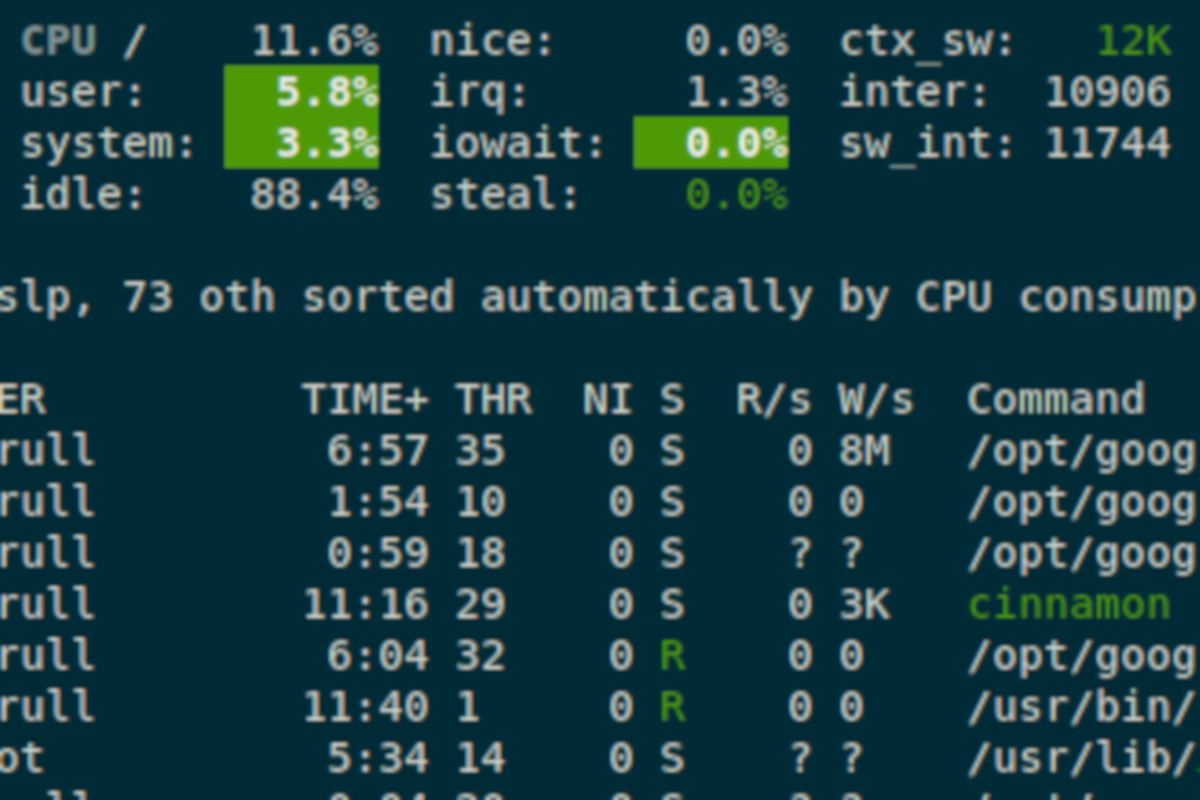
W poniższym poście przedstawię kilka przydatnych narzędzi do monitorowania systemów Linux
Pierwszy na warsztat idzie vmstat
Przykładowe użycie:
vmstat -w 2
gdzie:
- 2 – oznacza interwał w jakim ma się odświeżać
- -w – oznacza wide mode

Jakich informacji nam dostarcza vmstat?
procs:
- r – liczba działających procesów
- b – liczba uśpionych procesów
memory:
- swpd: zajęta pamięć swap
- free: pamięć wolna
- buff: pamięć użyta jako bufory
- cache: pamięć użyta jako cache
swap:
- si: Ilość pamięci zaczytywanej z dysku na sekundę
- so: Ilość pamięci zapisywanej na dysk na sekundę
IO:
- bi: Liczba bloków odczytanych z urządzenia na sekundę
- bo: Liczba bloków zapisanych na urządzenie na sekundę
system:
- in: Liczba przerwań na sekundę
- cs: Liczba context switches na sekundę
CPU:
- us: Procent CPU na operacje użytkownika
- sy: Procent CPU na operacje systemu
- id: Procent CPU nieużywanego
- wa: Procent CPU oczekujących na operacje IO
- st: Procent CPU poświęcony na swap
Jak widać vmstat daje nam pełny dostęp do niezbędnych dla nas informacji
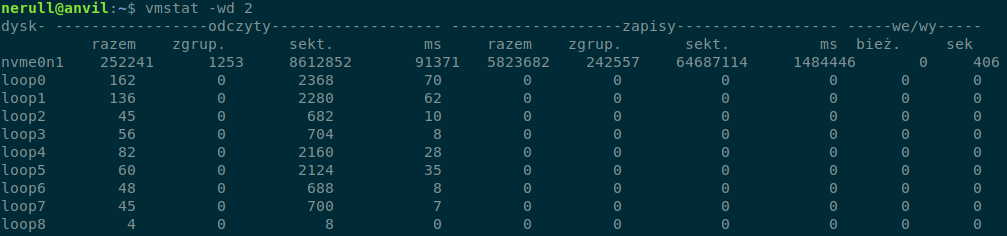
Jeśli chcemy bardziej szczegółowych operacji o operacjach na dysku możemy uruchomić vmstat w następujący sposób:
vmstat -wd 2
Drugim narzędziem jest dstat
Standardowo uruchominy dstat przedstawia nam następujące informacje:
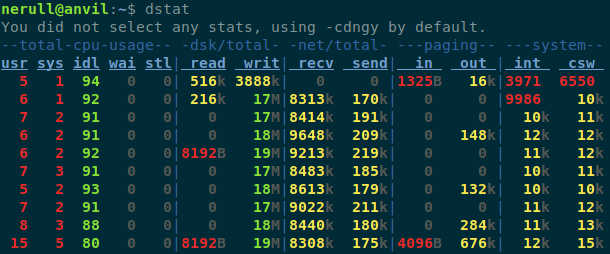
- Zużycie procesora
- Transfer zapis/odczyt na dysk
- Transfer zapis/odczyt na sieci
- Systemowe: przerwania i context switches
Wykonując taką komendę: dstat -pcymsdrn mamy wszystkie te same informacje co w vmstat tylko na kolorowo i z zaokrąglonymi wartościami co ułatwia czytelność
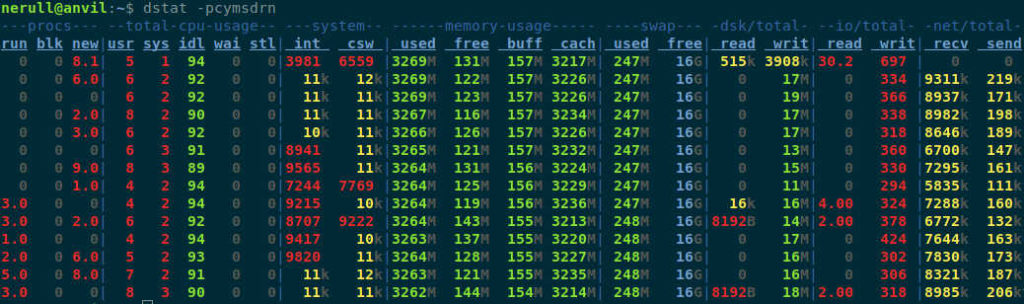
Dodatkowo mamy jeszcze inne opcje, takie jak:
- –aio – statystyki z operacji asynchronicznych
- –sock – operacje na socketach (tcp/udp/raw/frd)
- –tcp – bardziej szczegółowe informacje o socketach TCP
- –udp – bardziej szczegółowe informacje o socketach UDP
dstat dostarcza nam jeszcze pluginy:
- –battery – stan naładowania baterii
- –cpufreq – temperaturę każdego z procesorów
- –disk-avgqu – średnia wielkość kolejek oczekujących na dyski
- –disk-avgrq – średnia wielkość kolejek oczekujących na dyski
- –disk-tps – liczba transakcji odczyt/zapis na dysk
- –disk-util – procent procesora poświęcony na operacje IO
- –disk-wait – średni czas oczekiwania w milisekundach
I wiele innych
Przydatne może być również dodanie czasu metryki, szczególnie jeśli chcemy dane z monitoringu porównać z np, wykresami czasów odpowiedzi naszej aplikacji
dstat -pcymsdrnt
mtr – narzędzie do monitorowania jakości połączeń z wybraną usługą/hostem
np:
mtr craftsoft.eu
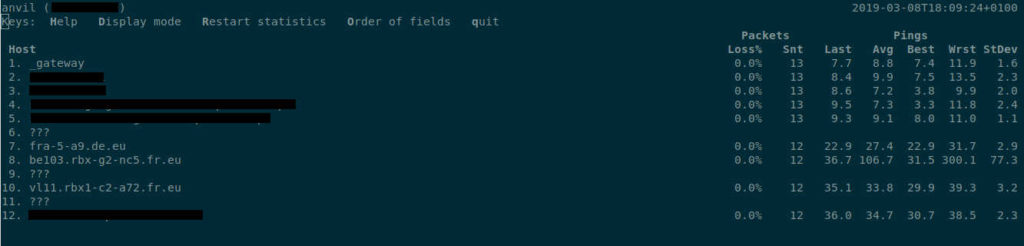
W ten sposób możemy prześledzić trasę jaką przebywają nasze pakiety i gdzie są największe straty. Przydatne do diagnozy utraty pakietów i opóźnień pomiędzy naszymi usługami, dane są pokazywane w postaci raportu lub w czasie rzeczywistym.
Jeśli chcemy zrobić raport to wykonujemy takie polecenie:
mtr -w -r -c 5 craftsoft.eu
gdzie:
- -w – wide mode
- -r – format raportu
- -c X – liczba powtórzeń – wymagane dla trybu raport, inaczej nam się nic nie zaraportuje